

I had the pleasure of attending the 'Update' developerconference on November 14 and 15 2024, and I have two goals for this writeup;
- Is this a candidate conference for you? https://www.updateconference.net/
- A subjective taste of the presentations I joined, based on my notes.
Surroundings:
Prague is a very beautiful city, with a lot of old architecture, partly because it was not bombed during World War 2.
Anecdotally, the prices for food and drinks are considerably cheaper than in Norway (about 1/2 to 3/4 of the price), but stuff like electronics are only somewhat cheaper, although this can vary considerably.

The conference itself was hosted in a 4 star conference hotel, in which I stayed, and that is itself situated inside a big shopping mall, some 25 minutes away from the old square in the city centrum, by tram. It has most of the stores you would normally want, many restaurants and a big plus for me; a very good gym that was free of charge for hotel residents, including a small pool.
Last year I went to Warsaw in Poland and its Developer Days conference: https://2023.net.developerdays.pl/main-conference/
I then also attended a pre-conference workshop with Nick Chapsas called Effective testing in C#, which was great. 📺
Warsaw had a somewhat similar lineup of talks, but I must say that the Update conference had generally better food and organization.
Sessions:
To me, it is important to put some energy upfront, into selecting the sessions I attend. I want to find that Goldilock Zone of being inspired, learn something new, but also be rational about its practical relevance for me in my current and future projects. Sometimes, a catchy abstract about something delightfully new, turns out to be short-lived and niché, with little practical use on my part.
Tracks: https://www.updateconference.net/en/2024/schedule
So the main disclaimer is that this content is based mainly upon my notes and research upon those notes, hence not entirely accurate, and contains just a simplified fraction the actual talk, so please inform me of any errors.
For a bit more context; I consider myself primarily a backend developer in the Microsoft sphere, with a special interest in SQL Server (and security engineering, although little practical work in the last 9 years). If I fiddle with frontends, I prefer it to be Blazor these days.
I choose to mention all the sessions I attended, not just the ones I thought was good. Some of the talks I describe in more detail, others very superficially, if at all. It is not meant to be balanced 🤷🏽♂️
Application Insights: The Tool You Never Knew You Needed
Isaac Levin, Microsoft
This topic is very relevant in my daily work for my current client.
There was a nice introduction to the subject of logging and telemetry, but as I'm already somewhat familiar with this subject, the real takeaway for me in this talk was that you can enable something called the Snapshot Debugger.
As long as you have connected App Insights and have turned the feature on, then you can basically opt for downloading a file that contains a lot of data regarding the current issue you investigate, for example an exception, and open it in visual Studio.
Also, you can add what is called a "snap point", in visual studio, kind of like a breakpoint on steroids, but one that is inspectable in production, as a little postmortem in itself.
Then you will have more context and readability, for example what modules was loaded, local variables etc.
I think this can be quite handy, especially in production code that can be, shall we say, quite sensitive to having a debugger attached.
A drawback is that it can be costly to store many 130 megabyte snapshots, albeit you can enable adaptive sampling to store less data.
Basics Designs and How We Got Them Wrong
Adam Furmanek
This was a collection of tips/advice, and started out with a dissection of the Liskov Substitution principle from SOLID, then going into importance of explicit contracts, etc..
My impression was that this is quite recognizable stuff, intermixed with some new theories. I left the session quite early, because it did not quite resonate with what I had subjectively expected.
Instead I peeked into this next session.
Identity Management in the cloud from a Developer's Perspective
Daniel Krzyczkowski, Formula5
Quite a nice, practical session, that went through some options for securing assets in the cloud.
If I remember correctly, the most interesting part for me, was using Bicep to set up Managed Identities; especially the user-kind.
This is where you handle the lifecycle yourself instead of it living and dying alongside the resource. This can have benefits, for example where you want to assign rights to multiple developers running locally while accessing SQL server's in the cloud.
Smart Components in Blazor - Spice Up Your Forms with a Pinch of AI
Kajetan Duszyński, Jit Team
Its been a while now, but last time I did some frontend, it was with (Mud)Blazor. This session was like an update from a similar session I attended in Poland's Developer Days conference in Warsaw last year, although this was less practically oriented.
Takeaway: Smart Components can be a nice addition to your toolbox for sprinkling in some A.I.
Hardening ASP.NET Core Web applications
Wesley Cabus, Xabia
I have worked with security for a few clients before, including having to actually create a token service, but those were in the early days of the SAML protocol.
This session was a nice rundown of how to leak as little info as possible to adversaries, including:
• Remove server and framework identification by renaming: cookies, local storage state and framework specific HTTP headers.
• Use Cookies more securely: HttpOnly, SameSite (strict, lax, none, not set)
• Browsers know that our site always uses HTTPS: HSTS (Strict-Transport-Security), max-age, includeSubDomains, 302 vs 307, preload.
• Disallow running our pages in an IFRAME to protect against clickjacking: X-Frame-Options (deny, Sameorigin, frame-ancestors CSP), X-Content-Type-Options, X-Xss-Protection.
We would like to have our site explicitly list where all its sources should come from, and with whom it is allowed to interact.
(The Army of the) 12 Monkeys: a tale on reliable web app (RWA) patterns and 12 factor apps
Mike Martin, Cloud Architect, Microsoft
I think it contained important stuff that is well worth a recap;
While not exactly new, the 'Twelve-Factor Manifesto" is a set of best practices for building and deploying scalable, maintainable, and portable cloud-native applications.
I guess the twelve points is worth a recap, so I shamelessly copy them here:
- Codebase: One codebase tracked in version control, with multiple deployments. Each service should have a single code repository, ensuring consistency and enabling CI/CD practices.
- Dependencies: Explicitly declare and isolate dependencies. Applications should never rely on system-wide packages; instead, use package managers to list dependencies in code, ensuring portability.
- Config: Store config in environment variables. Configuration, including secrets and settings that vary by environment, should be separate from code and stored in environment variables.
- Backing Services: Treat backing services (databases, queues, caches) as attached resources. These should be replaceable without code changes, treating them as loosely-coupled, swappable resources.
- Build, Release, Run: Separate the build and release stages. Create a clean pipeline where code is built, combined with config into a release, and then run as a distinct stage.
- Processes: Execute the app as one or more stateless processes. Any data that needs persistence should be stored externally in a database or cache, ensuring horizontal scalability.
- Port Binding: Export services via port binding. Web apps should be self-contained, exposing HTTP as a service on a specified port without depending on a specific web server environment.
- Concurrency: Scale out by running multiple processes. An app should use process types to handle different workloads (e.g., web, worker), scaling each as needed.
- Disposability: Maximize robustness with fast startup and graceful shutdown. Applications should be able to start quickly and shut down gracefully, enabling fast scaling and resilience.
- Dev/Prod Parity: Keep development, staging, and production environments as similar as possible. Minimize gaps to avoid environment-specific bugs, aiming for consistency in dependencies, services, and automation.
- Logs: Treat logs as event streams. Logs should be unbuffered outputs to standard output, where they can then be captured, indexed, and analyzed by external logging tools.
- Admin Processes: Run admin/management tasks as one-off processes. These tasks (e.g., database migrations, console commands) should be separated from the core app processes and triggered manually.
What was also mentioned, was different resources from Microsoft around WAF (Well Architected Framework), and patterns like:
Strangler Fig, Queue-based load leveling, Health endpoint monitoring, Retry, Cache Aside and Circuit Breaker.
There also exists guidelines from Microsoft especially for mission-critical applications.
Closing the loop: instrumenting your .NET applications with OpenTelemetry
Alex Thissen, Cloud Buster
Another practical presentation about an important subject. Very relevant to almost all projects nowadays, and we in Novanet has had some internal presentations regarding some of the same subjects before, for example Jaeger, that can neatly visualize trace information across services.
Perhaps the key takeaway I made note of, was:
You can use API shims that lets you use OpenTelemetry-concepts in code, and that there are different names for the same constructions, between OpenTelemetry and Microsoft.NET:
Tracer = ActivitySource
TelemetrySpan = Activity
SpanEvent = ActivityEvent
Link = ActivityLink
SpanContext = ActivityContext
For metrics, its all about numbers.
Use namespace System.Diagnostics.DiagnosticSource.
It's also possible to unit-test diagnostics since netcore8👍🏽
Objecthierarchy conceptually: An (OpenTelemetry)MeterProvider provides access to a (.net) Meter that creates a (.net) Instrument that reports to a (.net) Measurement. inject with IMeterFactory (new in .net8)
Use Prometheus (time-series database) for metrics locally, and Azure Monitor in the Microsoft cloud, and Grafana for reading and displaying.
For logging , consider Seq locally. I'm a big fan of Seq and Serilog myself, and if not used in the current project, I'm inclined to have a git stash ready, with Seq in a docker container, and structured logging bootstrapped, should the need for more involved debugging sessions arise.
Application Insights SDK => bound to AppInsights
versus
OpenTelemetry => not bound to one provider, and should be easy to switch out.
Questions and Answers with the speakers

Rockford Lhotka developed the CSLA.NET framework back in 2002, and I remember some colleagues using it keenly not long after release. The brunt of the questions from the audience was regarding A.I. and most of the panel was cautiously positive, I believe.
I approached Roland Guijt from the Netherlands during a break, because I have seen many of his technical courses on Pluralsight, and was actually a bit starstruck ✨ He turned out to be a very nice and talkative guy in person.
Identity Management in the cloud from a Developer's perspective
Daniel Krzyczkowski, Formula5
He went through a lot around managed identity in Azure, and I thought his points regarding local development closed a gap or two for me.
Especially using DefaultAzureCredentials that will check places in a set order, for credentials, starting with environment variables, then local devtools like visual studio.
Also creating a Microsoft Entra group for local development seems like a good idea. Then you can add developer accounts as members, and then add permissions to resource, resource group or subscriptions.
AI, FHE, ZKP, TEE and zkML, all the hype and... .NET
Konrad Kokosa, author: Pro .NET Memory Management book
So, this was a whirlwind tour of a lot of different technologies, let me mention the highlights:
- SpecLang: Ripped from their website, your specification, or "the spec", is the main source of truth for your program, and this is what you will be maintaining. It's a structured Markdown-like document of what you want of your program, penned out in only the necessary level of detail. If one has experience with ChatGPT or similar chat systems, it's natural to be sceptical of this vision: pure conversations with LLMs have many problems, e.g. unpredictability, flakiness, occassional basic coding errors, poor skills in writing build setup and config, etc. That's why we are building SpecLang as a non-trivial, end-to-end tool chain around the model, combining the LLM with classical algorithmics, static analysis and fault-tolerance techniques.
- Cursor, a fork of Microsoft VS Code editor, but centered around developing with artifical intelligence.
- ZKP (zero knowledge proof). Actually I read about ZKP in Bruce Schneiers book "Applied Cryptography" around 1998, in short Alice prove to Bob that she knows something, without actually revealing it to Bob. The math can be quite involved, one example was to prove that you did a speedrun on a specific demo-file, without actually revealing the demo-file. Although algorithms have become faster, it's still ~10 000 times slower than running the demo file at normal speed.
Interestingly, he also relatedly mentioned a recent paper, "zkLLM: Zero Knowledge Proofs for Large Language models" that sets out to help with the challenge of how to verify the outputs of LLM's, while keeping their parameters secret. One example is law enforcement querying an LLM for illegal answers, but to uphold in court, it must be undisputably proven that it was this exact LLM that provided the answers, all while the actual training parameters are still kept secret as part of the A.I. developers intellectual property.
• ZAMA - image filtering on encrypted data using fully homomorphic encryption. Basically doing operations on encrypted data without without first need to decrypt it.
Really interesting technology, huggingface have functionality where you can upload a picture, that's encrypted, apply a filter, and then send back to the client which can decrypt it.
https://huggingface.co/spaces/zama-fhe/encrypted_image_filtering
I tried, and it works as advertized, although as is the case with much cryptography, it can be hard to verify.
Also, the Apple ecosystem can actually recognize what encrypted images contains, in other words, label them.
https://machinelearning.apple.com/research/homomorphic-encryption - pvCNN: privacy-preserving and verifiable convolutional neural network testing. It let's parties, for example, collaboratively test the performance of an A.I. model specialized in video,
without revealing neighter the test-video itself nor the models proprietary parameters. Builds upon the aforementioned zero-knowledge proof, as well as other stuff.
.NET Aspire: The new way to be cloud native with .NET
Isaac Levin, Microsoft
He gave the tour about why Aspire is good for building cloud-native apps.
What I found perhaps most newsworthy, is toolkits made by the community, including downloading an Ollama container on startup and client integrations for OllamaSharp (.NET bindings for the Ollama API).
Let none survive! - How to test our unit tests with mutation testing
Stefan Pölz
This was a deep dive into Stryker.NET which allows you to test your tests by automatically inserting bugs into your test-covered code, and then run your tests for each bug, to see if they are failing or not.
I found this to be one of the more interesting sessions, both because I'm a fan of testing thoroughly, but also because this concept pf mutation testing is quite new to me. A downside is that it can take a long time to run your covering tests on each permutation of your code.
And the report it creates might typically generate more work, as you would inspect each uncatched change and decide if one or more tests should be changed to catch this "bug", or if it's something you can ignore, and then maybe filter it out in later runs.
In essence, for each mutation of your production code, you want at least one test to go red, else the "mutant"-survive. A good tip is to configure Stryker to run only the critical parts of your test-covered code.
https://stryker-mutator.io/
Turbo Charging Entity Framework Core 8: Performance
Chris Woodruff, Real Time Technologies
Basically a digest of this:
https://learn.microsoft.com/en-us/ef/core/performance/
15 years of insights from a TDD practitioner
Dennis Doomen, author of the Fluent Assertions library
I really like TDD, and try to use it in my workflow where I feel I can, and found this talk to be super-interesting.
Dennis listed his take on test-driven development;
- A design technique.
- Design your code to be very testable.
- Allow you to test things in isolation.
- Help you design your code properly.
- Give you and others confidence
- Can be used as documentation
- Keep you out of the debugger hell.
He also laid out his pragmatic approach to the practice, which is a bit more involved then the usual red, green, refactor:
- Design Responsibilities first, don't write the test first. Draw up architecture, draw classes, example: how do the API function and how is it connected.
- Then write the first test.
- Then Generate stubs (simulations of components under test)
- Then should fail (for the right reason)
- Implement
- Ensure test succeeds
- Look at alternative scenarios
- Repeat twice
- If you see something occurring three times, it might be a pattern, before that, keep tests separated.
- Refactor
- Back to 1.
Treat tests as specifications.
Test coverage is a means, not an end. Super-generally, 70% code coverage is on the right track.
If you have to rewrite a lot of tests when you refactor, that might be a code-smell. Try to test end-results, and try not to test specific method calls, as this ties your test more to the implementation, thus making it more brittle. Use "grey" box testing, instead of black = no assumptions, or white = many assumptions.
Use multiple levels of testing
Choose the right scope, find the right scope.
You must understand the architecture and the seams in your code.
The Unit is the scope you decide it to be.
If reusable unit, then expand the scope.
SO you don't need to rewrite tests when you refactor.
Remember: Test reusable things separately, not reusable then test in a larger scope.

Sync to use same folder structure and naming in tests as in production code.
Use concise fact-based naming:
Not: When___Then
Best: An_expired_token_is_not_valid()
Short and logical!
Emphasize cause and effect:
// Arrange
// Act
// Assert
Make it clear, show the important stuff in the test, hide the unimportant stuff.
Tests are first class citizens.
Try to stay away from fixture classes, because they allow you to put and hide away stuff that often can grow too much.
Have clear assertions.
FakeLogCollector: Do test logs statements, if they are important.
Don't overuse mocking, and use at the right boundaries.
There is value in running your pipeline locally, and Nuke (https://nuke.build/) might be beneficial.
Don't accept flakiness. Consider dotnet-retest: https://github.com/devlooped/dotnet-retest/
If you do have sometimes long running, flaky tests, consider running:
dotnet test --blame-hang-timeout 5m --blame-hang-dump-type full
(if more than 5 minutes, flagged as "hang", giving more diagnostic output, including a memory dump that can be inspected with dotnet-dump - https://learn.microsoft.com/en-us/dotnet/core/diagnostics/dotnet-dump)
Doomen closed off with a book recommendation, "Working effectively with legacy code" by Michael Feathers. I have read a some of it, and it's great.
🌱 Should I dare recommend a TDD book myself, it will definitely be "Growing Object-Oriented Software, Guided by Tests" by Steve Freeman and Nat Pryce.
Although with examples in Java, it's what really sold me on TDD, with it's inherent plant-metaphor with emphasis on steady, organic, incremental growth, and how the fast feedback loops keeps your code healthy and growing in the right direction.
I approached him 1:1 after the public Q&A for his take on Stryker.NET and his practical experience on mutation testing;
He said that he uses a script to run mutation tests with Stryker to the main branch sometimes, because it's so slow. And it will uncover new problems. It can useful, but filter for relevancy.
Transforming .NET Projects with AI Capabilities Using Semantic Kernel
Louëlla Creemers, VP & university teacher
She described Semantic Kernel as "open source, efficient middleware for building A.I. agents and integrate the latest models".
The prior day, an audience member had suggested that "Semantic Kernel is like an ORM for AI" (ORM, as in "Object Relational Mapper, like Microsoft's Entity Framework).
I knew some introductory stuff regarding Sematic kernel, so I did not attend that prior session, but I found the analogy interesting, but with limitations.
Stuff like the abstractions, being cross-system, increasing productivity and behaving like a bridge into a common interface; all this plays nicely into how ORM's operate.
But Semantic Kernel does quite a bit more, as it manage orchestration, prompt-chaining, embeddings, and deals with probabilistic, not deterministic, structures, which have a dynamic and evolving, rather that a static 1:1 mapping.
Louëlla did quite an interesting, practical session, where she used Semantic Kernel towards OpenAI's LLM, but with Meta's Ollama as a backup LLM model, that also can be run locally, which is handy.
She showed examples in C# with using plugins for date and time, adding your custom types with builder.Plugins.AddFromType("space"), and the interesting experimental Semantic Kernel Agent Framework.
So with a ChatCompletionAgent, you create multiple agents, for example user and manager, and you can tell it to terminate once the manager approves the product. Uses AgentGroupChat.
There was a comparison as well between Semantic Kernel vs OpenAI SDK;
Semantic kernel uses multiple models while OpenAI is stuck with just one.
Semantic Kernel can orchestrate it's plugin, and can be paired with the new multi-agent runtime autogen-core inside AutoGen: https://devblogs.microsoft.com/semantic-kernel/microsofts-agentic-ai-frameworks-autogen-and-semantic-kernel/
Coding in the Cloud: A guide to GitHub Codespaces
Barbara Forbes, Azure MVP.
For some years, I have known about pressing the . (period) key when viewing a github repo in a browser, which will bring up a web version of Visual Studio Code running entirely in the browser, where you can edit and debug the code.
But Github Codespaces takes this quite a bit further, because it also spins up an entire cloud-based development environment, fully containerized and tightly integrated with your repositories. You can use the web or the desktop version of VS Code to access it, and easily share workspace for dicussions or pair-programming. Codespaces has terminal access, debugging, and extension support.
On github, press the "code"-dropdown, chose the Codespaces tab, and press "Create codespace on [your main branch]" - presto!
AWS Cloud9 is a similar development environment in the Amazon cloud.
But the small part in the end, was what really caught my interest:
Github Copilot Workspaces! 🥳
A Copilot Workspace is a task-oriented development environment with some agentic behavior, that lets you brainstorm and plan multiple tasks, that can be implemented as a set of code-changes spanning multiple files and issues, with access to commands like build, test and run, all with Copilot chat capabilities as well
That is in technical preview, and I have got access, let me just display how it works.
🚀 Quite some years back, I made a Win32 App I called "Alpharaketti" using the "GDI+ managed class interface" for .NET framework, that is a demo of a spaceship in a gravity field, which can be rotated and have thrust using arrow keys and spacebar, all from scratch, including (suboptimal) mathematics for vector forces and rotation, as a tribute to the classic Amiga game we spent countless hours playing in my youth: 💓 https://www.turboraketti.org/tr/index_e.html
What I did not come around to do at the time was adding sound effects.
Let me just show a screenshot from Copilot Workspaces when I asked for help to incorporate thrust sound:
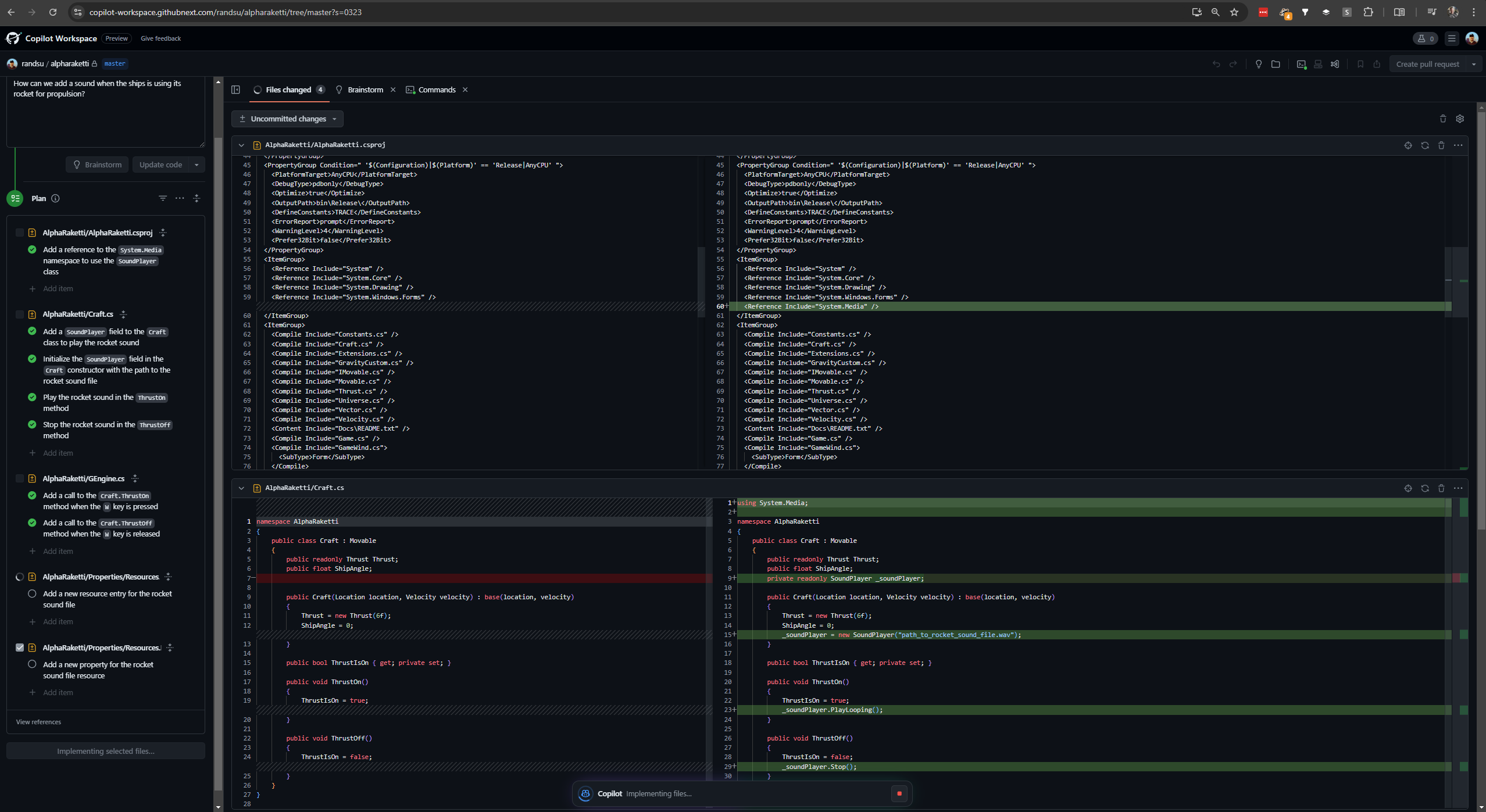
You can brainstorm with the A.I., kind of like you can with the collaborative canvas in OpenAi's ChatGPT, then have it lay out tasks that can be reasoned about and changed, and added as issues and delegated to others.
Also you can ask for the tasks to be implemented in code or directly, and also share this snapshot of your codebase with others, as well as createing pull requests or pushing directly to branches.
The helptext for the "plan":
The plan outlines the set of files that need to be added, edited, deleted, or renamed, in order to perform the current task. It presents this as a list of files, each of which includes a set of specific changes that need to be made to them. Just like the exploration, the plan is fully editable, and allows you to add, edit, and remove both files and steps from the list. Additionally, you can add General notes to the plan, which act as file-agnostic instructions you'd like Copilot to consider (e.g. Use async/await). If the plan doesn't look quite right, you can either regenerate it to get a new version, or refine the Proposed specification in order to add extra detail.
Supercharged Search with Semantic Search and Vector Embeddings
Giorgi Dalakishvili, Tech lead at Space International
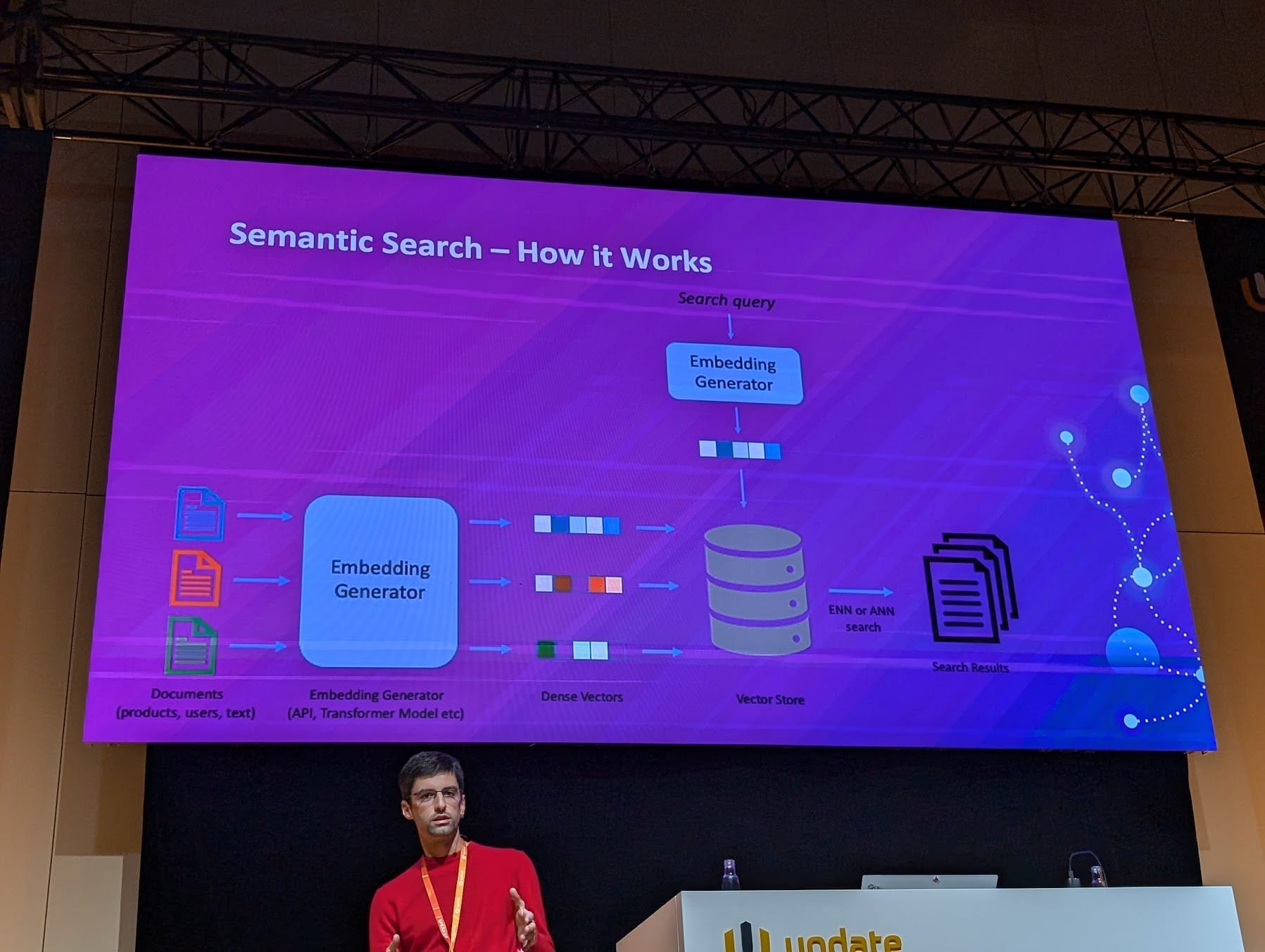
This lowkey, hands-on talk was simply one of the best talks I have ever attended.
Giorgi, working at a fintech company, seemed extremely well versed and hands-on, and had a stellar explanation of the technology stack involved, from vector theory and up into practical code for storage with Entity Framework Core and PostgreSQL tables. 🥇I had Feynman vibes, to be honest.
Lexical search = exact match. Sematic search = match on meaning.
Simplified, a vector-database contain a geometric landscape with multiple dimensions, potentially a huge number of them.
Each dimension is describing a property of a quantified scalar value that describe one property of for example a word, a sentence or whole documents.
Embeddings map textual data to this high-dimensional space, represented as vectors, where similar meaning means closer.
So to determine the relevance of search results, you can compare the search query's embeddings to the embeddings of documents in the search index.
The closer they are geometrically, the more their sematic meanings are similar. One metric for this is the Euclidean distance, which is a generalization of the Pythagorean theorem for finding the hypotenuse in a triangle, √(a²+b²)
You can run a model locally, for example with smartComponents.LocalEmbeddings.NET (from Microsoft) or SentenceTransformers (with Python).
Different databases include:
Vector:
• Chroma
• Pinecone
• Milvus
• Qdrant
• Weaveiate
Relational:
• PostgreSQL
• Oracle Database 23ai
• Azure SQL server
Other:
• Redis
• Mongo
• Couchbase
• Elasticsearch
Giorgi did a demo with SQL Server, where he was able to store vectors as regular scalar columns (I think he used FLOAT), but loaded them as C# objects into memory, and searched there.
Then he used PostgreSQL, witch have the advantage of being extensible. So he used the extension pgvector, and this enabled him to use a vector similarity search for Postgres at the database engine level, in other words, as a set-operation. You can pick from euclidian, cosine of inner product as different ways to measure.
Also, he demonstrated that you can set vector indexes, which will speed up these potentially gigantic searches by a great deal.
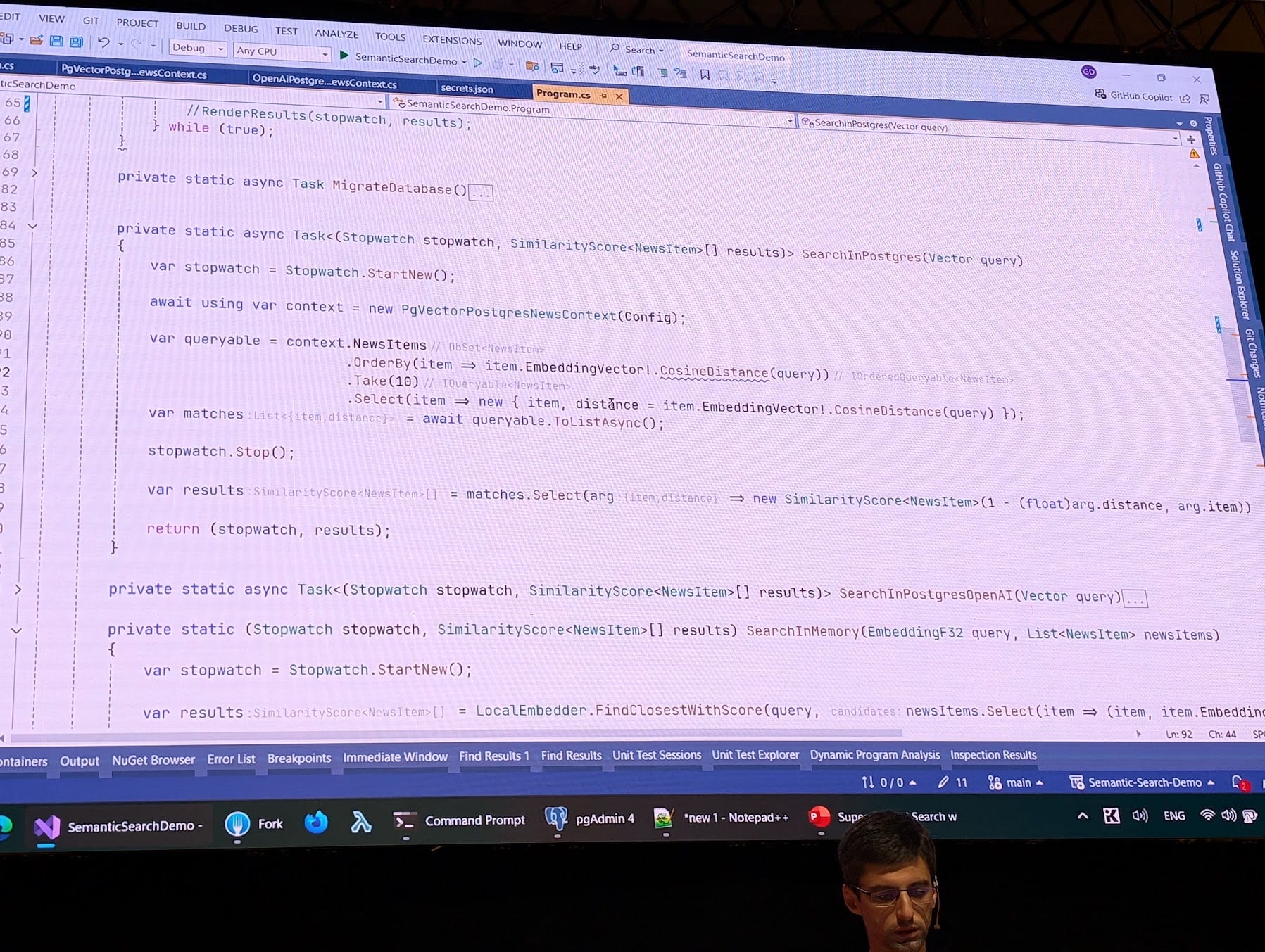
Why pgvector?
• collocate vectors (metadata) together with the data, in same database table for example
• fast, effective cost
• ACID compliance
• operational advantages
• backups
• better observability and tooling
• many languages supported
Then he demonstrated practical usage of pgvector, how to install, add as column, insert vector data and finally query.
A package called 'pgvector-dotnet' supports pgvector in C# with Dapper and Entity Framework Core and more.
I noted something about a Visual Studio query plan visualizer supporting pgvector, but I cannot seem to find that anywhere. Anyway, they exists in various forms for Postgres and inspecting the query plan is a good idea, especially with an ORM like EF Core.
Giorgi also did a C# demo using OpenAI, where he used api-calls to generate embeddings with 1536 dimensions, to what must have been their model 'text-embedding-ada-002'.
👏🏽
Exploring Source Generators in .NET
Jared Parsons, Microsoft C# Compiler Lead
Source generators was introduced in C#8 and .NET5.
Basically, you can add classes to your c# code, which you decorate and then register the dll as an analyzer in the project file, and this enables you to generate new files at build time.
It cannot modify your code directly, but is added to the compilation pipeline.
Some use cases are boilerplate mappings, serialization, automatic API generation, logging, DI-injections etc..
Jared explained that an important design decision they reached early on, is that you can only generate new files. Also, generated code cannot talk to each other directly and you cannot decide upon their ordering.
It is a hard enough to get this to run fast enough as it is, without opening the rabbit hole of complexity that that seemingly inconspicuous functionality would call for.
Source generators is for some customers very sought after, and is used in some really big projects out in the wild, and it's critical that they are as performant as possible.
🛠️ To properly accommodate source generators, the compiler team had to add a new c# type modifier, namely "file". It effectively avoid namecollisions because these types and their nested types, are only visible within the file where they are declared.
One interesting usage is for example source code generation for automatically implementing IEquatable using only attributes:
https://github.com/diegofrata/Generator.Equals
There are source generators for any calls in the Win32-space, that automates those platform Invoke calls, DLLImports with extern etc..
If you want to debug source generators, unit tests are the way to go.
Setup a compilation of the syntax tree, run generator on the compilation, get the generated code and assert it.
And finally, partial properties are in .NET9 preview 6: https://github.com/dotnet/core/blob/main/release-notes/9.0/preview/preview6/csharp.md
Conclusion
I really enjoyed the conference and have plenty to follow up on 🤩. It was technically well-produced, and many of the talks were highly relevant to my background. There's a good chance I’ll return in the future.
🎲🎲🎲🎲+
