
TL;DR
- In a relational database, primary keys are essential. Don't roll without them.
- Primary key is by default promoted to the clustered index for the table.
- Table rows are physically stored in clustered index order on disk.
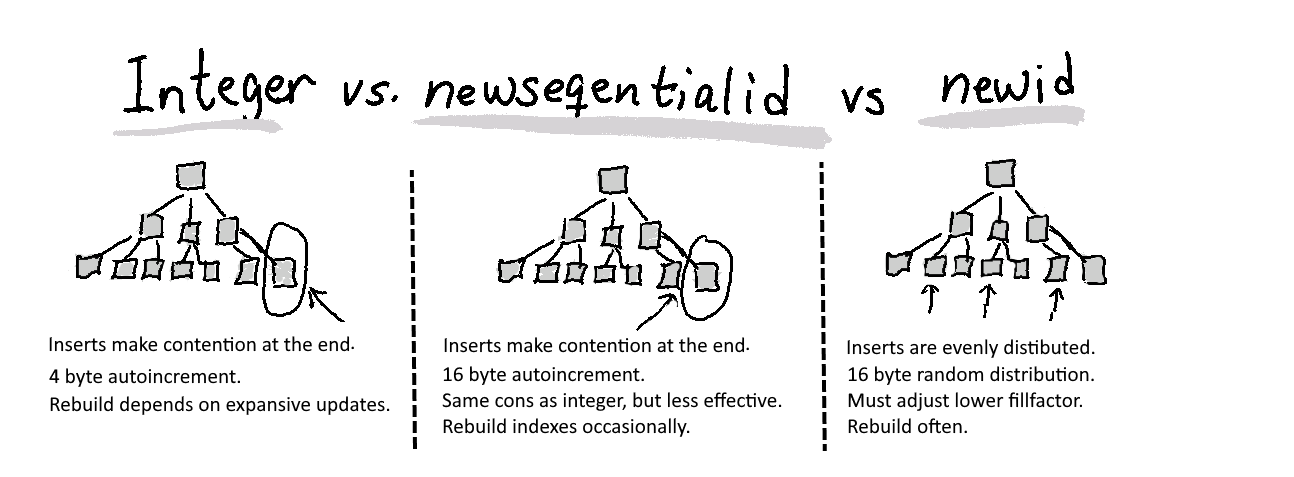
- An ever-increasing integer key is always generated chronologically in order, so every new row is added at the end, which usually is ideal; see left pane below.
- Random GUID primary keys comes in random order, so new rows often have to be squeezed in between existing rows when stored physically, which can be ineffective and costly; see right pane below.
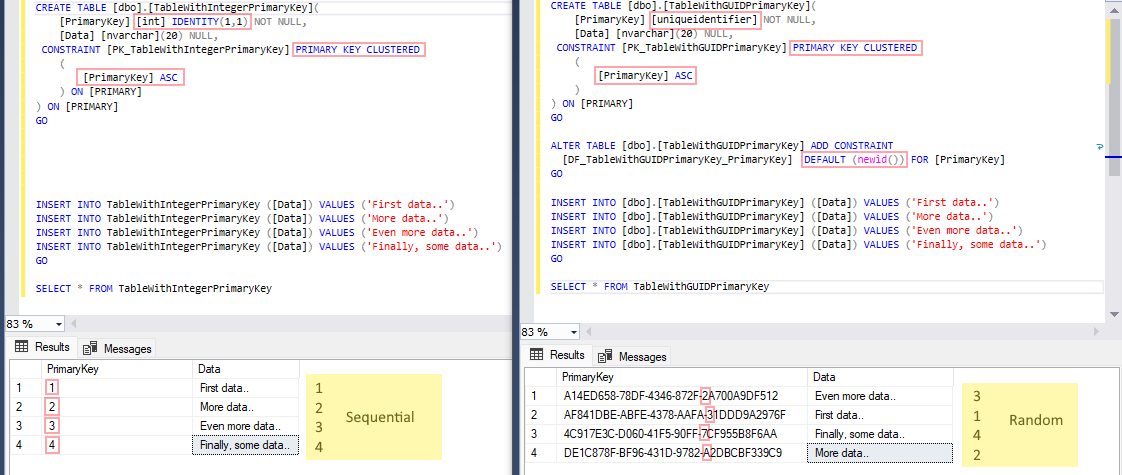
- ❗Unless very light circumstances (not production environment, few rows/inserts, light load, rare access etc..), you should administer random GUID clustered indexes with care.
- 👉 A good option might instead be to introduce an ever-increasing integer identity key, and instead make your random GUID an unique, non-clustered index column, thus enabling both excellent internal, technical performance as well as global identification. 🦄
- Not intended to explore the complex realm of database index design in full detail, but peeks progressively deeper under the hood to provide insight.
- A simplified introduction to some theory and internal implementation details is helpful for understanding a problem that can easily slip under the radar, and which gets progressively worse in big tables with many inserts and/or updates to cluster index key.
Performance is magical
The performance of a modern relational database management system always blew me away. It still strikes me as feeling like some kind of magic. That much data. So complicated queries. And even still... those lightning fast execution times. In the computer science classes I remember we learned about the theory of different kind of sorting and lookup trees, like binary trees, M-way trees and so forth. We also implemented some of them. But what about actual, real life practice? Where the boots hit the ground, in the professional arena? It's been very interesting to investigate and dissect this mystery, to peek into a few parts of implementation inside balanced search-trees as used in row-level indexes within the Microsoft SQL Server system. But, there are pitfalls lurking in the complexities...
A good idea
For example in the Domain Driven Design-paradigm, it's often tutored that the application should set the logical identifier for an entity - not have some infrastructure like a storage layer decide that. And it's handy that its globally unique, thus a GUID is a great fit; it's conceptually clever to have an identifier that's unique across tables, databases, servers and companies.
Amongst other things, integrating, synchronizing, importing and exporting between different locations can be much less painful and effective, simply by having one identifier to which is unique across different realms.
Era of code-first
In the present era of code-first, you are most likely using some kind of an object-relational mapper like for instance Microsoft Entity Framework.
So far, so good.
And the ORM will happily accommodate that C# type GUID as the identifier of your table's rows. And shield you from some of the technical database implementation details, which, inherently is a good thing, so that not every developer also need to be a database administrator, like in the old days.
What is a clustered index?
A clustered index basically stores keys and physical pointers to a node in the level below. The key values in a node effectively becomes thresholds. The search key is compared to these thresholds. If the search key
- is smaller than the smallest threshold, the leftmost pointer is chosen.
- is greater than the greatest threshold, the rightmost pointer is chosen.
- falls into the range of key values between any two consecutive thresholds, the pointer between them are chosen.
- is exactly the same as a threshold, then the pointer to the immediate left of that treshold is chosen (as a convention).
Then the chosen pointer is followed to a node in the level below (aka. a "hop"). That node might be yet another intermediate index node with key values and pointers only. In that case, the same process as above repeats. But if instead the node below is a leaf data node, in the bottom, then that node contains the data rows as well as the their key values, and the search is complete. The data is hence "clustered" together, in the exact order of their index key values.
But the actual operation underlying the search, might be a select, an insert, an update or a delete. And when that operation changes the data pages, the clustered index tree above might have to change as well.
In other words, the top root and intermediate nodes below contain tables of index keys and pointers, and the leaf nodes contains the full row data (except when columns are too big to fit, then the datapage itself also contain pointers to special data pages, but lets keep this simple).
It's a balanced+ tree, meaning that there can only be allowed a maximum difference of one intermediate node layer in any path. The tree is continually flattened, to keep the number of hops needed to lookup an index, as low as possible, for all different key values, and therefore as fast as possible.
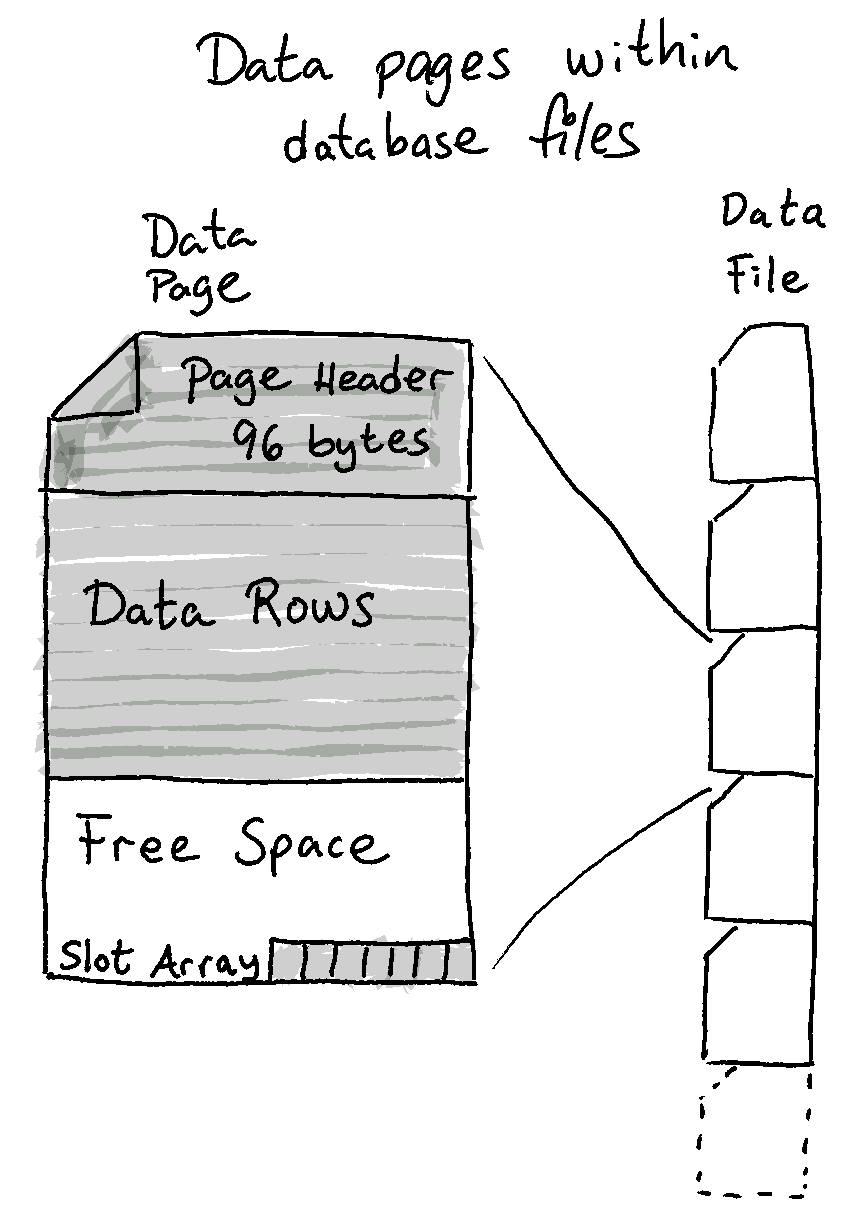
Nodes consists of data pages within physical files
What does an index tree look like?
Here is a simplified example with a 5-way B+ tree.
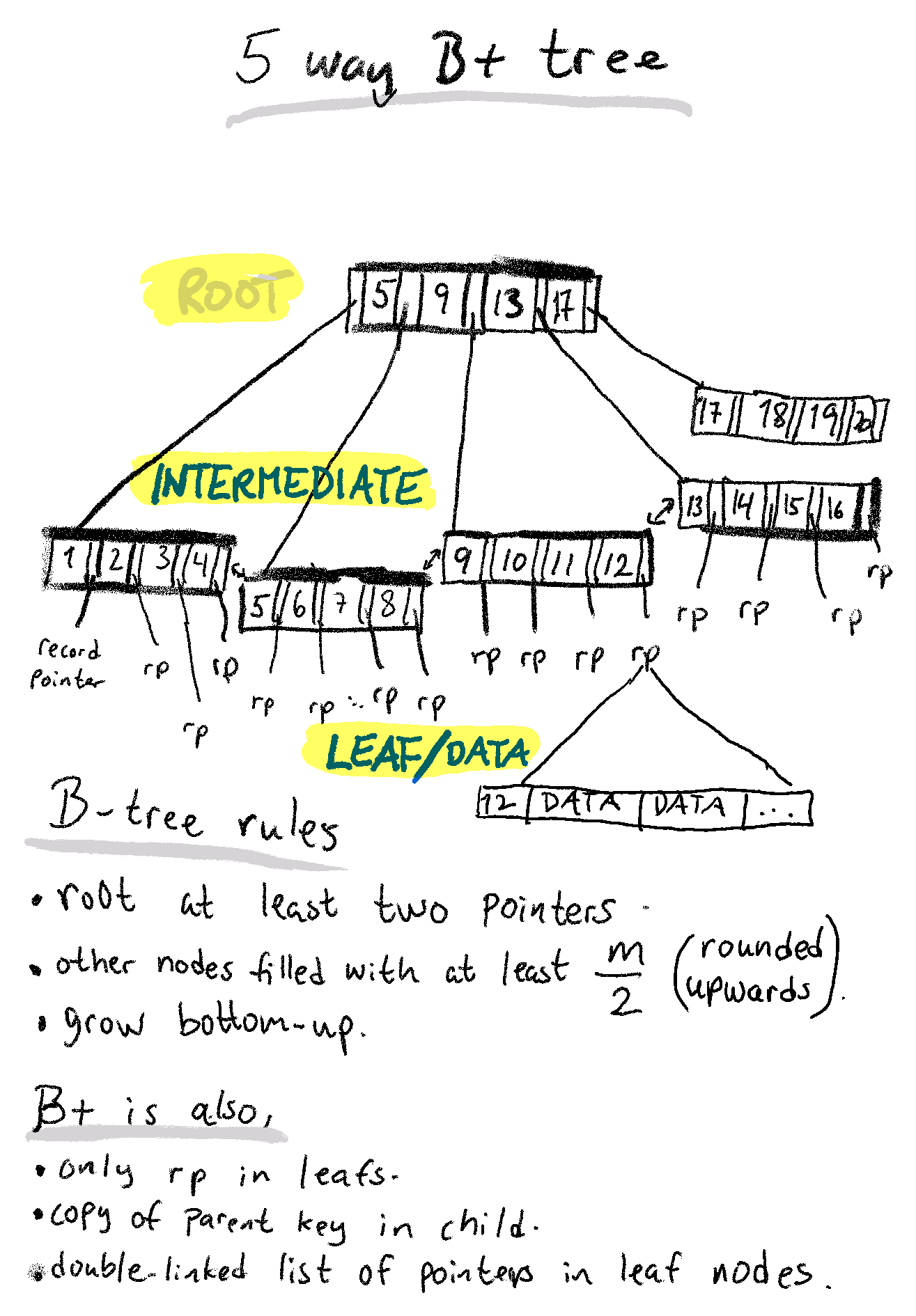
The offset array is an internal pointer to the index rows, which grows backwards, from the end and up. It's is much more efficient to manage such an array of internal pointers that's in (backwards) order, than to move the individual index rows around on disk.
Realistic SQL Server B+ index tree
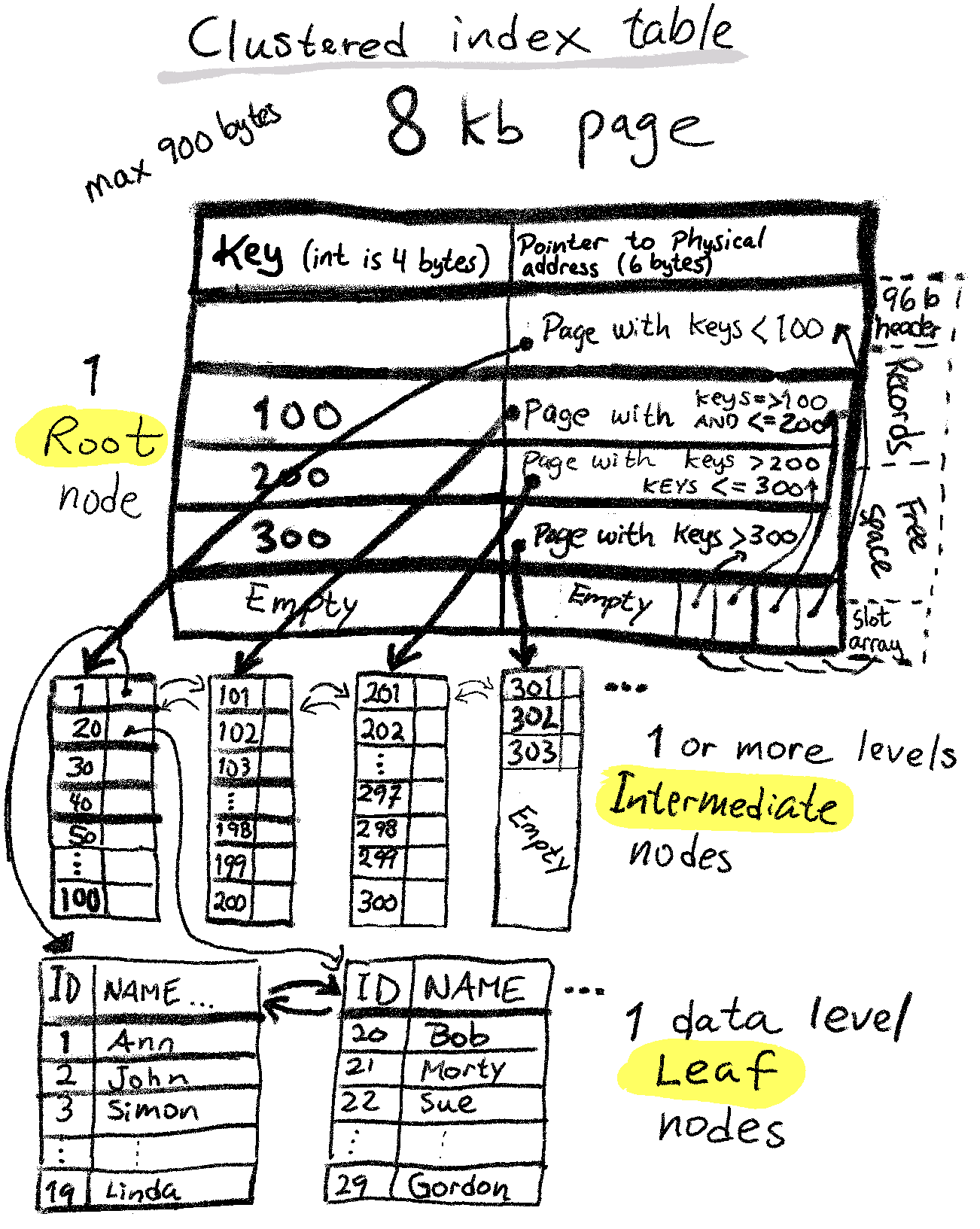
A small index key size will let us store many index rows (keys + pointers) in each 8-KB index node page. A bigger key size will use more bytes per row, resulting in less index rows - this can possibly mean more intermediate node levels, even many more for tables with many rows.
That's all fine and dandy. We can understand that a 16 byte GUID key will take up four times as much space as a 4 byte integer, which makes the number of levels and hops bigger and slower for big tables.
More details on how index keys are searched
When the engine (decides it should) do a search based on any index key, it starts from the top, hop down to the next node level (vertically down in the tree), by following a 6 byte node pointer in the index row. Pointer adresses consists of data file id, page id and offset id within that page.
Which pointer is decided based upon whether the key value in question is less than or greater than that row key. There is a pointer below and a pointer above all key values. And after some hops, it lands in the bottom node layer, the so called leaf node layer, and this is also where the actual rowdata is usually stored (binary large objects like varchar [max] and variable length columns that overflow the 8 kilobyte page limit are also stored here, but in different pages). If you inspect a query plan, this operation is called an "index seek" and is the most effective search method, and is what you should strive for.
Intermediate index pages are double-linked, and when they are sequentially searched forwards or backwards (horizontally in the tree), it's called an "index scan". Data pages are also double-linked, and when scanned sequentially it's very costly, require much I/O, takes longer to process, should be avoided, and that operation is called a "table scan".
Primary key as default clustered key
If you are using Microsoft SQL Server as your database system, the default behavior is that the primary key is automatically set to be the table's clustered index - which now is a random, long string of letters and numbers.
There can be zero or one clustered index per table.
This clustering key also gets used as the lookup value for any nonclustered indexes. The table's datarows are stored in the order of the clustered index (actually as part of the clustered index itself; within the leaf nodes in a balanced tree). You can also set a clustered index on something other than the primary key.
Hops required for different index keys
If we use a single 4 byte integer as key, and adding 6 bytes as well for the child page pointer plus 2 bytes for the slot array entry, we get 12 bytes for each index row. If we take 8 060 bytes and divide by 12, we get 671 index rows on each index page.
If we use a single GUID instead, that's weighing in at 16 bytes bytes instead of 4, we get 24 bytes per row, which then give us 335 index rows per page.
With integers we then can accommodate 671 total datarows fitting in the root node, which must point to an intermediate layer, where all index keys also fit, pointing to data in the leaf node layer, giving only two lookup hops. If we expand to one more level, we can accommodate 671^2 = 450 241 rows, in three lookup hops.
The hops required for a (single) GUID key will increase more as row count increases, because the extra 12 bytes contributes to fitting only 112 225 rows in three lookup hops.
However, the max size of an index row is 900 bytes. So with an extremely big index key of 900 bytes, you can only squeeze 8 index rows into a single page, because 8060 / 900 is 8,96 which is just below, but not quite, 9 rows unfortunately... Doing 8 x 8 gives us only 64 rows that can be accommodated with three lookup jumps in the B+ search tree.
Bigger key is worse
A bigger key hence means fewer index rows per page. An integer takes up only 4 bytes, while a GUID is - 4 times larger.
The number of datarows at the leaf level determines how many levels of intermediate nodes are needed in the "balanced+" index hierarchy.
(SQL Server actually makes a tradeoff in that paths from the foot node to the bottom are allowed to differ with at most one level, indicative of the fact that upkeep of a perfectly balanced tree is not worth the effort)
Identity incremental key
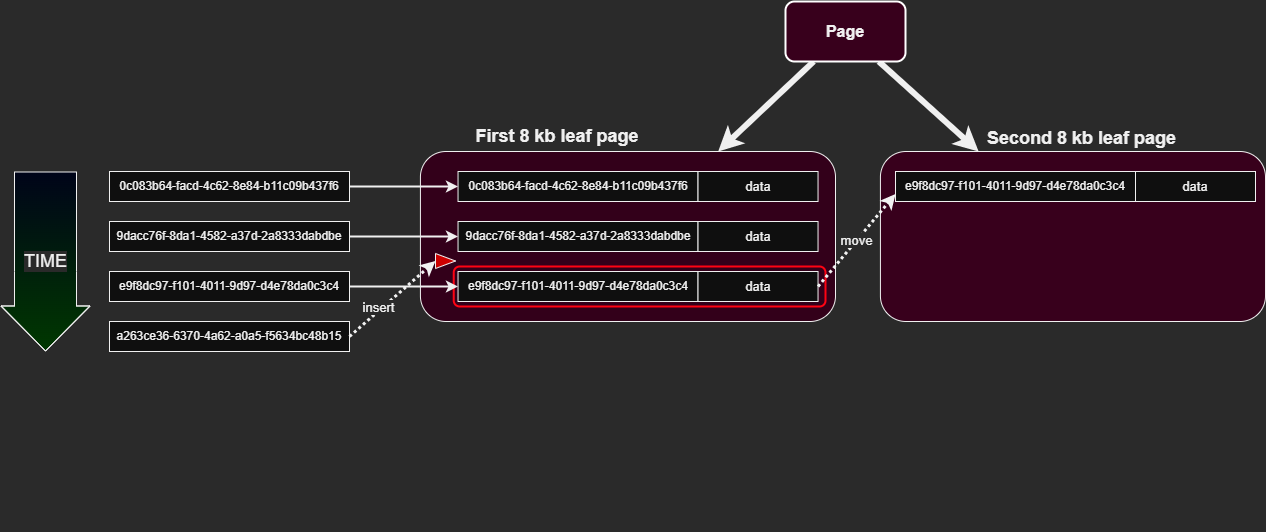
An ever increasing index key will always get inserted at the end of the leaf page, which makes the leaf pages most compact, which in turn means fewest hops to find the data.
When the engine is always inserting at the very end, it's likely that some degree of competition and contention of the same physical page on disk - by different processes who all want to write and update - will happen. They incur locks on the populate data-page, so that their data can be written. Some workflows makes updates to recently inserted rows, which can make this worse; read on.
Expensive expansive updates
An "expansive" update means to expand row data, for example by updating a nullable VARCHAR from NULL to 50 bytes; let's say an "UpdatedBy"-column. If the data page no longer have room after the expansion, the engine will have to make room, by performing a so called "page split", that adds a new physical data page on the heap, and then move about half the data therein. This is costly and it also makes gaps in the physical ordering of the data - also known as index fragmentation.
Whenever inserts, updates or deletes are done, the engine will automatically balance the tree of index nodes according to it's rules.
Random GUID keys
When you use a random globally unique value as index key, in this case a UNIQUEIDENTIFIER column type that gets generated by using the function NEWID(), inserts are spread out more or less evenly across the index-values in the table. The physical table row data resides in the clustered index leaf nodes, that in turn are physical pages on the disk.
Now that each new key is random, there is a huge chance that the data page where this key belongs is full. And then the engine must do a costly page-split, as mentioned before. Possible very often. Possibly all the time new rows are inserted. Which inherently worsen performance. Whether this inefficiency is negligible or unacceptable, depends on the specific case in question.
Physical order matters
When data pages on disk are not in physical order, it can increase disk operations, by having to resort to many smaller contiguous chunks being read instead of fewer big ones. When we now use solid state drives with few moving parts, the problem is however not quite as detrimental as when magnetic spinning drives was dominating the server-racks.
Index fragmentation can also have an effect on which strategy the engine decides for performing the task at hand, also known as deciding on the best possible query execution plan. Current statistics about fragmentation is one of many factors that may influence this delicate decision.
Using surrogate clustered index
Let me propose a possible solution to the problem of having a GUID clustered index key. Eat the cake, and have it too. Kinda.
1. Set the clustered index to a surrogate column,
which ideally is an integer (or bigint) that automatically increases by 1.
2. Then set a unique, non-clustered index on that GUID column,
for example named "PublicId", with t-sql type uniqueidentifier.You will have good technical performance as well as having a unique logical identifier present and queryable.
But, if you will - lets dig just a tad deeper.
Fillfactor to the rescue?
If you insist; an option when using GUIDs is to adjust the fill factor for the index. When new data pages are allocated, you can reserve written, blank space in the data on disk, which is reserved for new insertions or expanding updates. The fill factor is a percentage of how full the data page is filled when created as part of an index-modifying command, like recreate or rebuilding the index itself! New data pages are always filled to the maximum during a regular insert.
A fillfactor of 80% makes about 20% of initial rows empty, and they are distributed between used row space. This means that there is a better chance that there is room for a data row when inserting a random key - possibly reaping the benefit of much less pressure on the last data node, because writing is now distributed across the whole index key range and hence across the range of pages.
An increasing GUID aka. newsequentialid
You can instead of a random GUID use a GUID-like number that's also globally unique, has 16 bytes, but comes in semi-sequential increasing order.
❗When you use DEFAULT (newsequentialid()), the GUIDs might very well begin at a lower range when you restart the Windows operating system. (One of the operating systems' network card's MAC addresses, together with some value that might change on reboot, are apparently involved in the formula).
Or, perhaps less viable, but still possible; opt for generating sequential GUIDs externally as strings, for example from your dotnet code, by using Window's UuidCreateSequential-function (but remember to reorder bits so that they are aligned with the aforementioned, peculiar SQL Server format for the uniqueidentifier datatype). And then converting your imported guid-string in t-sql: CONVERT(uniqueidentifier, @YourExternalStringVariable).
Newsequentialid() is a bit faster to generate, because newid()-function is wrapping the windows-function UuidCreate(), which must randomly produce more bits/operates within more degrees of freedom, than it's counterpart newsequentialid(), which wraps windows-function UuidCreateSequential()).
⚠️Apart from global uniqueness, and the fact that it's not secure from cryptanalysis (algorithm is seeded with unique address of one network controller card, plus future values are predictable), a newsequentialid key is much like the integer key - except physically bigger, thus fewer are fitted into an index page, giving potentially more hops down the search tree. The lack of security regarding newsequentialid() can indeed be a showstopper in and of itself.
Don't skip maintenance plans
But as time goes by, and more rows are filling the pages, more pages are bound to split. When defragmentation is severe enough, the index will sorely need to be rebuilt or recreated, during which the physical order of pages on disk are realigned with the logical order of the values of the index key. That's what recurringly execution maintenance plans are for, in a shorter interval than that of the filling of the pages. Rebuild/reorganize at regular intervals and/or in relation to statistics such as the level of index fragmentation.
A warning on GUIDs and fillfactor
⚠️Be careful! If you use random GUIDs as clustered index, then you should lower fill factor below 100%, try in small steps and measure over time. You can easily do more harm than good. One of the reasons that Microsoft doesn't recommend lowering the fill factor below 100% in the general case, is that this blank space not only takes up disk space, but also cache space in memory and backups. If you lower fill factor from 100% to 50%, you roughly half the amount of actual rows that will fit within the 8 kilobyte pages.